SQL 相关
Last Update: 2023-08-26目录
建表
创建用户和数据库 (PostgreSQL)
创建用户 CREATE ROLE <user-name> WITH LOGIN PASSWORD '<pwd>';
修改用户的密码 ALTER USER <user-name> WITH PASSWORD '<pwd>';
创建数据库 CREATE DATABASE <db-name> WITH OWNER <user-name> TEMPLATE <template-db> ENCODING <encoding> LC_COLLATE '<collate>' LC_CTYPE '<ctype>';
比如 CREATE DATABASE <db-name> WITH OWNER <user-name> TEMPLATE template0 ENCODING UTF8 LC_COLLATE 'en_US.UTF-8' LC_CTYPE 'en_US.UTF-8';
根据已有表建表
最通用的 CREATE TABLE... 可以凭空建新表。
CREATE TABLE <table> AS <expr> 则可以从已有表建新表:
CREATE TABLE <new-table> AS SELECT * FROM <origin-table> WHERE 1=2创建结构与<origin-table>相同的表,复制结构,不复制数据CREATE TABLE <new-table> AS SELECT * FROM <origin-table>创建结构与<origin-table>相同的表,复制结构与数据CREATE TABLE <new-table>(<col1-new-name>, <col2-new-name>) AS SELECT col1, col2 FROM <origin-table>创建结构与<origin-table>相同的表,复制指定列的结构与制数据,但在新表中更改指定列的名称
查询
SQL92 和 SQL99 (SQL3) 的 JOIN
CROSS JOIN (笛卡尔积) 写法:
-- SQL92
SELECT * FROM t1,t2,t3;
-- SQL99
SELECT * FROM t1 CROSS JOIN t2 CROSS JOIN t3;
NATURAL JOIN 写法:
-- SQL92
SELECT * FROM t1, t2 WHERE t1.id = t2.id
-- SQL99
SELECT * FROM t1 NATURAL JOIN t2
-- NATURAL JOIN 可以自动连接两表中名称相同的字段
-- 它替代了 WHERE
JOIN ... ON ... 写法:
-- SQL92
SELECT * FROM t1, t2 WHERE t1.id = t2.id
-- SQL99
SELECT * FROM t1 JOIN t2 ON t1.id = t2.id
JOIN ... USING(col, ...) (SQL99 新增,是一种等值连接的简化形式) 写法:
SELECT * FROM t1 JOIN t2 ON t1.id = t2.id;
SELECT * FROM t1 JOIN t2 USING(id);
SELF JOIN (自连接) 写法:
-- SQL92 (还没有 AS 关键字)
SELECT * FROM table1 t1, table1 t2 WHERE t1.oid = t2.id
-- SQL99
SELECT * FROM table1 AS t1 JOIN table1 AS t2 ON t1.oid = t2.id
写符合 SQL92 标准的查询命令时,所有需要连接的表都被放到 FROM 之后,然后在 WHERE 中写明连接的条件。比如:
SELECT ...
FROM table1 t1, table2 t2, ...
WHERE ...
SQL99 在多表连接方面的写法更灵活,它不需要一次性把所有需要连接的表都放到 FROM 之后,而是采用 JOIN 的方式,每次连接一张表,可以多次使用 JOIN 来连接多张表,可读性更强:
SELECT ...
FROM table1
JOIN table2 ON ...
JOIN table3 ON ...
SQL99 采用的这种嵌套结构非常清爽,多表连接的层次结构非常清晰。
此外,SQL99 在 SQL92 的基础上提供了一些特殊语法,比如 NATURAL JOIN 和 JOIN USING 这些都比较常用,省略了 ON 后面的条件判断能 SQL 命令更加简洁。
JOIN 的方式
语言描述比较麻烦,可以直接查看这张经典图:
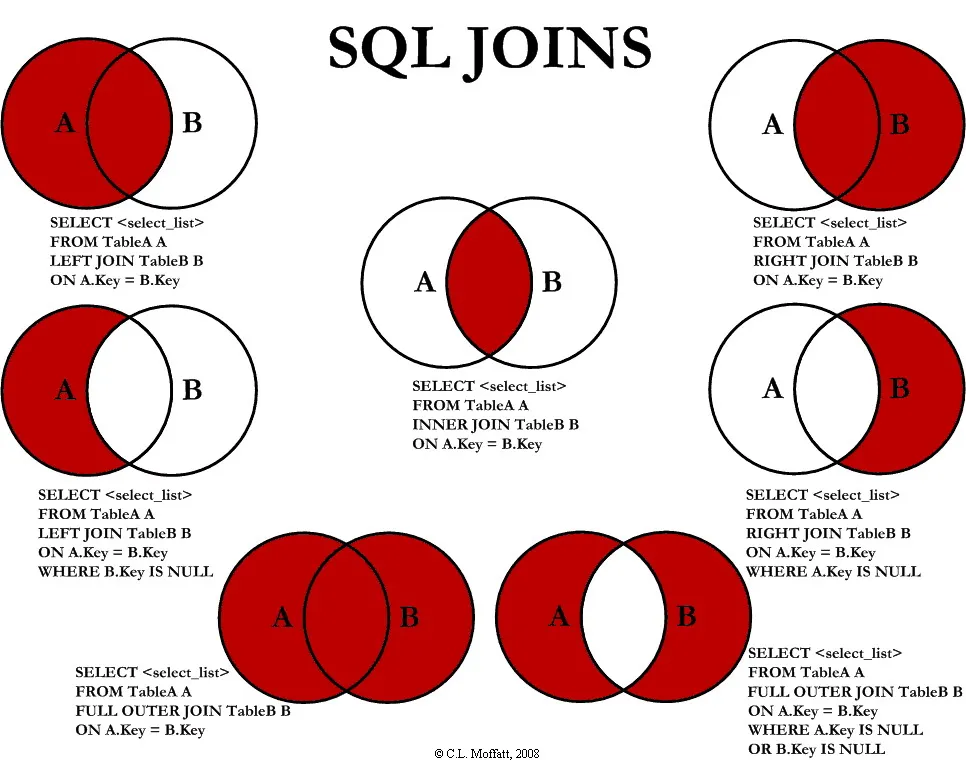
在 MySQL 中:
- SQL 解析阶段,RIGHT JOIN 被转换为 LEFT JOIN
- 在一些特殊情况下,LEFT JOIN 被转换为 INNER JOIN
- JOIN, CROSS JOIN, INNER JOIN 等效,都要先做 CROSS JOIN
DISTINCT
SELECT DISTINCT 的作用是去重:
SELECT DISTINCT country FROM user;会显示 user 表中记录的 country,不显示重复的 countrySELECT DISTINCT city, country FROM user;会显示 user 表中记录的 (ciry, country) 二元组,在去重时以该二元组为基准作比较- city 和 country 都相同的才会被去除,只要有任意一个不同就会被保留
HAVING 和 WHERE
HAVING 后的条件可以使用聚合函数,而 WHERE 后不能。
WHERE 的作用是在对查询结果进行分组前,将不符合条件的行筛掉。即,在分组前过滤数据。
HAVING 的作用是筛选满足条件的组。即,在分组之后过滤数据。条件中经常包含聚组函数,使用 having 条件过滤出特定的组。
GROUP BY
GROUP BY 必须搭配聚合函数一起用。
它的逻辑可以理解成,按照 BY 后指定的列把查到的数据分组,但每组只能有一条数据作为结果。聚合函数的作用就是从多条记录组成的组中,把要显示的部分计算出来。
LIMIT
LIMIT N: 取前 N 条记录LIMIT N OFFSET M: 跳过 M 条记录,返回 N 条记录。即,取 [M+1,M+1+N] 区间的记录。PostgreSQL 可用LIMIT N,M: 从第 N 条记录开始, 返回 M 条记录。即,取 [N,N+M] 区间的记录。MySQL 可用,PostgreSQL 不可用
IN 和 EXIST
SELECT * FROM table_a WHERE (id, num) IN (SELECT id, num FROM table_b where ...) 中的 IN :
- 相当于多个 OR 并列
- 其后有子查询时,先做子查询
- 适用于子查询返回的表小于 table_a 并且 table_a (最好) 有索引的情况
SELECT table_a.* FROM table_a WHERE EXISTS (SELECT 1 FROM table_b WHERE table_a.id = table_b.id) 中的 EXISTS :
- 只检查子查询是否有非 null 的返回
- 用主表中的每一行都被应用到子查询中
- 适用于 table_b 大于 table_a 并且 table_b (最好) 有索引的情况
显示所有的 sequence (PostgreSQL)
SELECT c.relname
FROM pg_class c
WHERE c.relkind = 'S' order BY c.relname;
通常,sequence 以 <table>_<column>_seq 命名。
删除
清空数据库 (PostgreSQL)
PG 中的数据库由多个 schema 组成,要清空数据库,只需要删除所有的 schema 并重建默认的 public schema 即可。
\dn 可以列出当前库中所有的 schema, \dn+ 可以查看每个 schema 更详细的信息。
删除 public schema DROP SCHEMA public CASCADE;
新建 public schema CREATE SCHEMA public;
把新的 public schema 授权给所有用户 GRANT ALL ON SCHEMA public TO PUBLIC; 。这句中的 TO 后面要跟特定用户名,跟 PUBLIC 意味着授权给所有用户。但要注意,PG 中没有 PUBLIC 这个用户, PUBLIC 只是用于指代所有用户的关键字。